
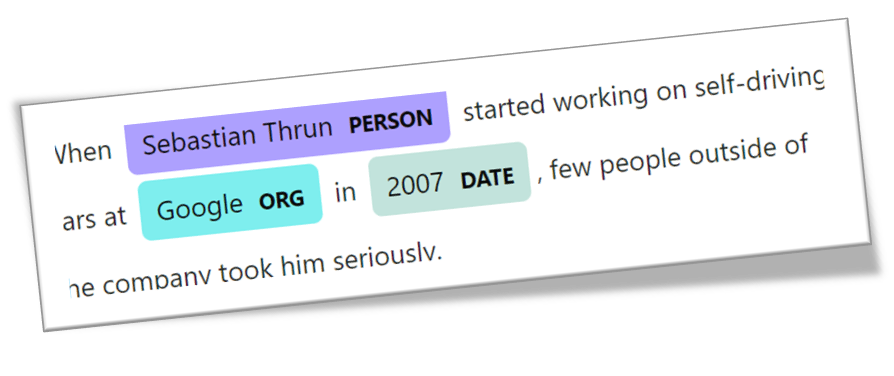
This is a name finder example for NERs (Named Entities Recognition) which is a nice way to find names and other things in the text based on a trained model. A basic training might be required.
Other NLP AI Contentserver Articles
Example Linguistic Features of NLP
Content Server NLP application examples
Content Server Autocategorizer
Content
Name finder
Lets first start with the example:
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("models"+File.separator+"en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior sales manager and John is his deputy";
String tokens[] = tokenizer.tokenize(sentence);
System.out.println("Namefinder example"+"\n");
System.out.println("Example sentence"+"\n"+sentence);
System.out.println("found"+"\n");
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("models"+File.separator+"en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
System.out.println("Position Name"+"\n");
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
} the example sentence is “Mike is senior sales manager and John is his deputy“.
Lets start this example
Namefinder example
Example sentence
Mike is senior sales manager and John is his deputy
found
Position Name
[0..1) person Mike
[6..7) person John
The Token “(0…1) person Mike” and “(6…7) person John” are recognized. In this example, the model ios “en-ner-person.bin”, which means, the Language is english and the model is trained on person names
Training
A training example is
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.Collections;
import opennlp.tools.namefind.BioCodec;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.NameSample;
import opennlp.tools.namefind.NameSampleDataStream;
import opennlp.tools.namefind.TokenNameFinder;
import opennlp.tools.namefind.TokenNameFinderFactory;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.InputStreamFactory;
import opennlp.tools.util.MarkableFileInputStreamFactory;
import opennlp.tools.util.ObjectStream;
import opennlp.tools.util.PlainTextByLineStream;
import opennlp.tools.util.Span;
import opennlp.tools.util.TrainingParameters;
public class NERTrainingExample {
public static void main(String[] args) {
System.out.println("NER person training example\n");
// reading training data
InputStreamFactory in = null;
try {
in = new MarkableFileInputStreamFactory(new File("train"+File.separator+"AnnotatedSentences.txt"));
} catch (FileNotFoundException e2) {
e2.printStackTrace();
}
ObjectStream sampleStream = null;
try {
sampleStream = new NameSampleDataStream(
new PlainTextByLineStream(in, StandardCharsets.UTF_8));
} catch (IOException e1) {
e1.printStackTrace();
}
// setting the parameters for training
TrainingParameters params = new TrainingParameters();
params.put(TrainingParameters.ITERATIONS_PARAM, 70);
params.put(TrainingParameters.CUTOFF_PARAM, 1);
System.out.println("Training parameters\n"+"TrainingParameters.ITERATIONS_PARAM 70");
System.out.println("TrainingParameters.CUTOFF_PARAM 1");
// training the model using TokenNameFinderModel class
TokenNameFinderModel nameFinderModel = null;
try {
nameFinderModel = NameFinderME.train("en", null, sampleStream,
params, TokenNameFinderFactory.create(null, null, Collections.emptyMap(), new BioCodec()));
} catch (IOException e) {
e.printStackTrace();
}
// saving the model to "ner-custom-model.bin" file
try {
File output = new File("custom_models"+File.separator+"ner-custom-model.bin");
FileOutputStream outputStream = new FileOutputStream(output);
nameFinderModel.serialize(outputStream);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// testing the model and printing the types it found in the input sentence
TokenNameFinder nameFinder = new NameFinderME(nameFinderModel);
String sentence = "Stefan Miller is a highly qualified specialist at Clouds working at a Content Server partner";
String[] testSentence =sentence.split(" ");
System.out.println("test sentence\n"+sentence);
System.out.println("Finding types in the test sentence..");
Span[] names = nameFinder.find(testSentence);
System.out.println(names.length + " names found");
for(Span name:names){
String personName="";
for(int i=name.getStart();i<name.getEnd();i++){
personName+=testSentence[i]+" ";
}
System.out.println(name.getType()+" : "+personName+"\t [probability="+name.getProb()+"]");
}
}
}When the example is run, the output is
NER person training example
Training parameters
TrainingParameters.ITERATIONS_PARAM 70
TrainingParameters.CUTOFF_PARAM 1
test sentence
Stefan Miller is a highly qualified specialist at Clouds working at a Content Server partner
Finding types in the test sentence..
1 names found
default : Stefan Miller [probability=0.586696461666961]At the end, there is a test sentence to see, if the training was ok.
The training data are 130 annotated sentences. The name the system is supposed to learn, is plain text and
My name is <START> Michael Hinterhofer <END>.The NER is defined by <START> and <END>.
See annotation examples on Github https://github.com/mccraigmccraig/opennlp/blob/master/src/test/resources/opennlp/tools/namefind/AnnotatedSentencesWithTypes.txt
As always, a lot helps a lot. The more sentences you have, the better. For production, you should contain at least 15000 sentences