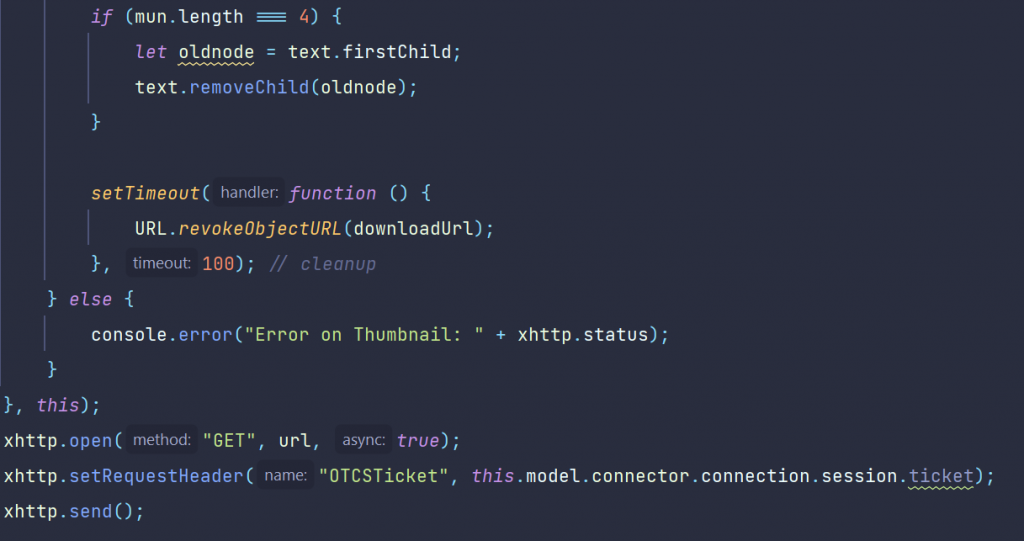
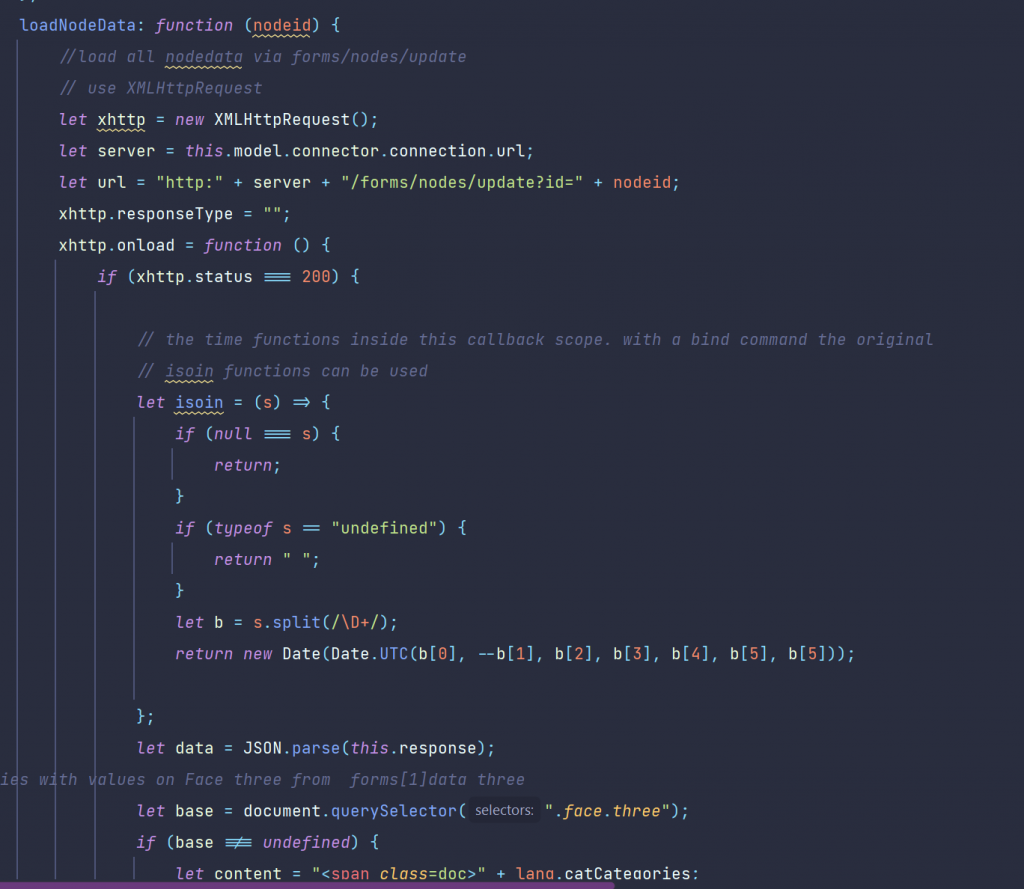
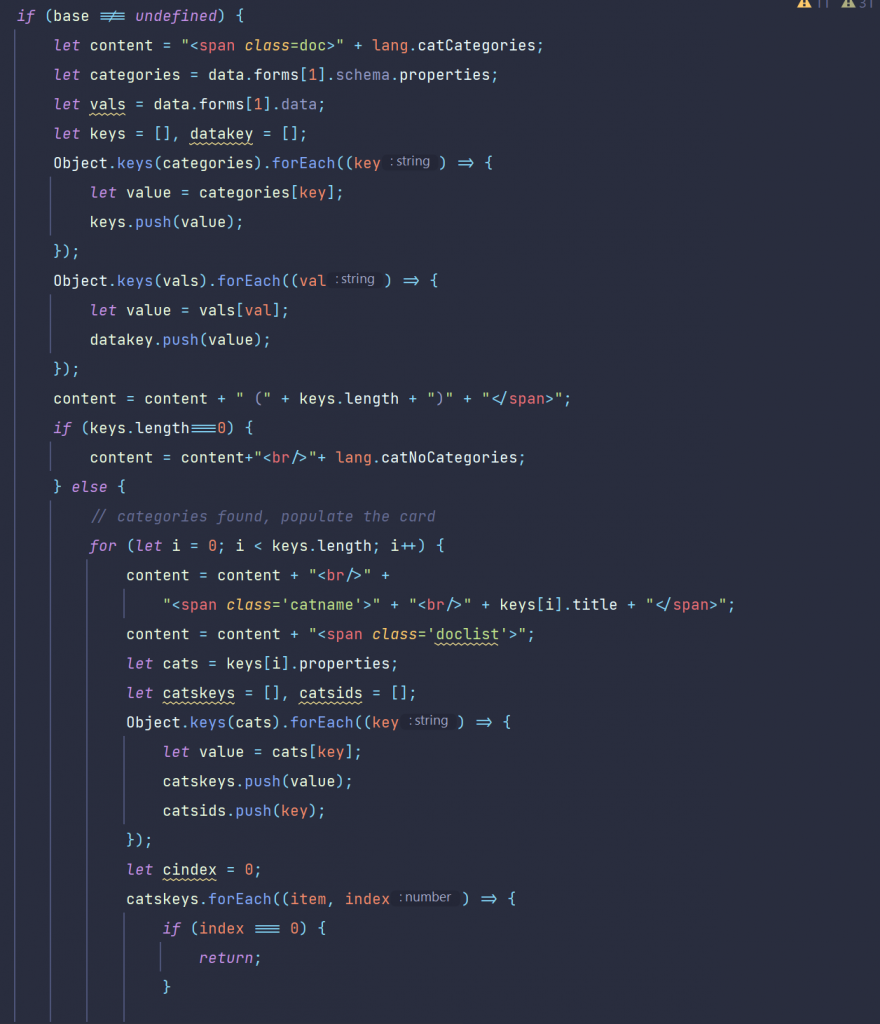
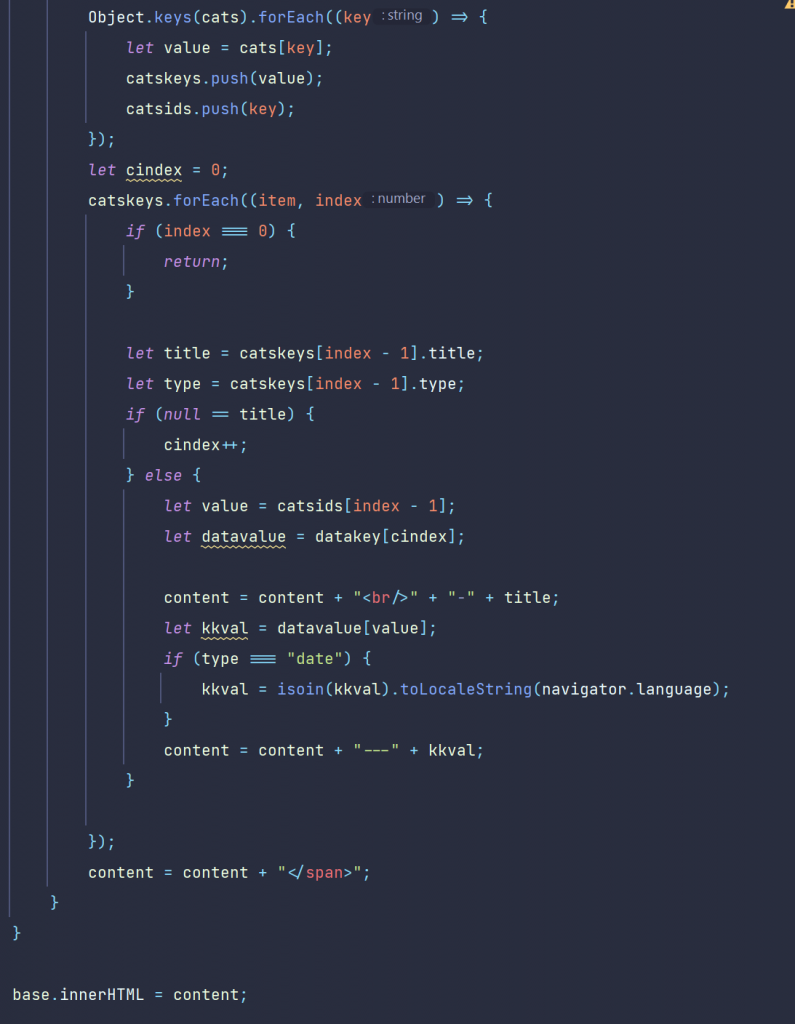
You might have noticed, that you need a tool to open a document and extract the content as pure text for further natural language processing (p.ex. the buildin Categorizer, linguistic examination, language detection or predicting something from your documents or finding names and locations from your documents ) downstream.
The answer is Apache Tika, a free tool from Apache.
But you as you can programm TIKA in JAVA (inside the Content Server or as a client), you can also use TIKA in the command line without any programming.
BTW: See the starting page of the openNLP series of articles here
The Tika application jar (tika-app-*.jar) can be used as a command line utility for extracting text content and metadata from all sorts of files. This runnable jar contains all the dependencies it needs, so you don’t need to worry about classpath settings to run it. So, no need for coding.
This is the usage-help documentation
usage: java -jar tika-app.jar [option...] [file|port...]
Options:
-? or --help Print this usage message
-v or --verbose Print debug level messages
-V or --version Print the Apache Tika version number
-g or --gui Start the Apache Tika GUI
-s or --server Start the Apache Tika server
-f or --fork Use Fork Mode for out-of-process extraction
--config=<tika-config.xml>
TikaConfig file. Must be specified before -g, -s, -f or the dump-x-config !
--dump-minimal-config Print minimal TikaConfig
--dump-current-config Print current TikaConfig
--dump-static-config Print static config
--dump-static-full-config Print static explicit config
-x or --xml Output XHTML content (default)
-h or --html Output HTML content
-t or --text Output plain text content
-T or --text-main Output plain text content (main content only)
-m or --metadata Output only metadata
-j or --json Output metadata in JSON
-y or --xmp Output metadata in XMP
-J or --jsonRecursive Output metadata and content from all
embedded files (choose content type
with -x, -h, -t or -m; default is -x)
-l or --language Output only language
-d or --detect Detect document type
--digest=X Include digest X (md2, md5, sha1,
sha256, sha384, sha512
-eX or --encoding=X Use output encoding X
-pX or --password=X Use document password X
-z or --extract Extract all attachements into current directory
--extract-dir=<dir> Specify target directory for -z
-r or --pretty-print For JSON, XML and XHTML outputs, adds newlines and
whitespace, for better readability
--list-parsers
List the available document parsers
--list-parser-details
List the available document parsers and their supported mime types
--list-parser-details-apt
List the available document parsers and their supported mime types in apt format.
--list-detectors
List the available document detectors
--list-met-models
List the available metadata models, and their supported keys
--list-supported-types
List all known media types and related information
--compare-file-magic=<dir>
Compares Tika's known media types to the File(1) tool's magic directory
Description:
Apache Tika will parse the file(s) specified on the
command line and output the extracted text content
or metadata to standard output.
Instead of a file name you can also specify the URL
of a document to be parsed.
If no file name or URL is specified (or the special
name "-" is used), then the standard input stream
is parsed. If no arguments were given and no input
data is available, the GUI is started instead.
- GUI mode
Use the "--gui" (or "-g") option to start the
Apache Tika GUI. You can drag and drop files from
a normal file explorer to the GUI window to extract
text content and metadata from the files.
- Batch mode
Simplest method.
Specify two directories as args with no other args:
java -jar tika-app.jar <inputDirectory> <outputDirectory>
Batch Options:
-i or --inputDir Input directory
-o or --outputDir Output directory
-numConsumers Number of processing threads
-bc Batch config file
-maxRestarts Maximum number of times the
watchdog process will restart the child process.
-timeoutThresholdMillis Number of milliseconds allowed to a parse
before the process is killed and restarted
-fileList List of files to process, with
paths relative to the input directory
-includeFilePat Regular expression to determine which
files to process, e.g. "(?i)\.pdf"
-excludeFilePat Regular expression to determine which
files to avoid processing, e.g. "(?i)\.pdf"
-maxFileSizeBytes Skip files longer than this value
Control the type of output with -x, -h, -t and/or -J.
To modify child process jvm args, prepend "J" as in:
-JXmx4g or -JDlog4j.configuration=file:log4j.xml.You can also use the jar as a component in a Unix pipeline or as an external tool in many other scripting languages.
# Check if an Internet resource contains a specific keyword
curl http://.../document.doc \
| java -jar tika-app.jar --text \
| grep -q keywordA nice thing about TIKA is the existence of other language ports like Python or Julia
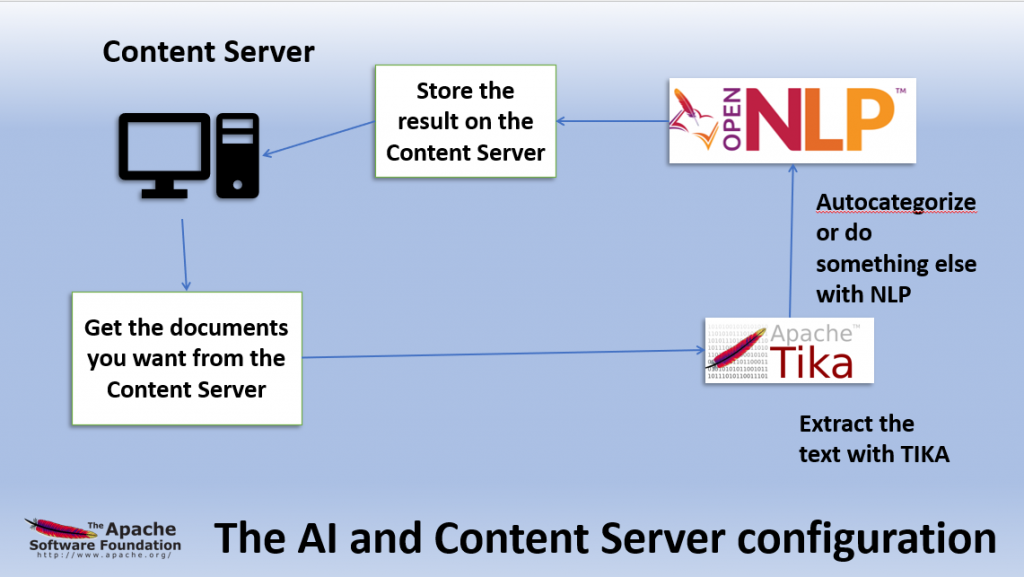
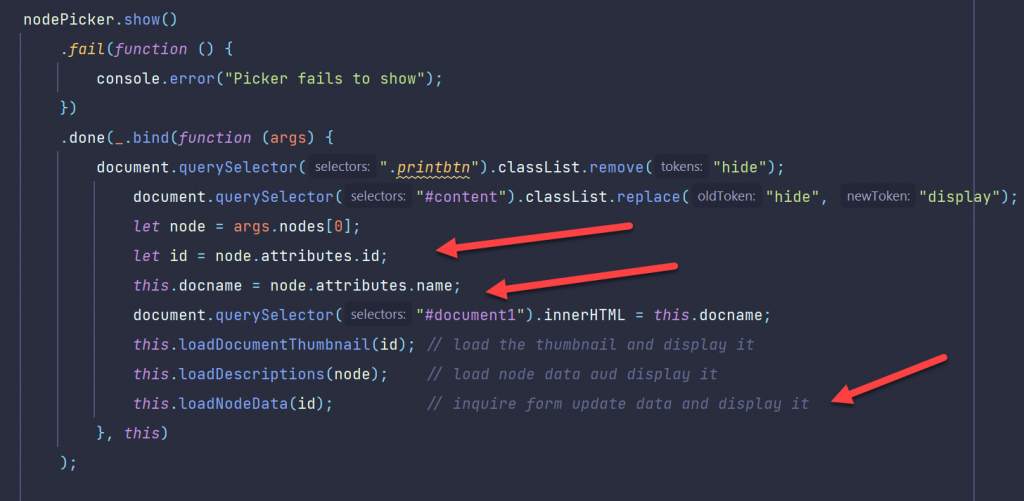
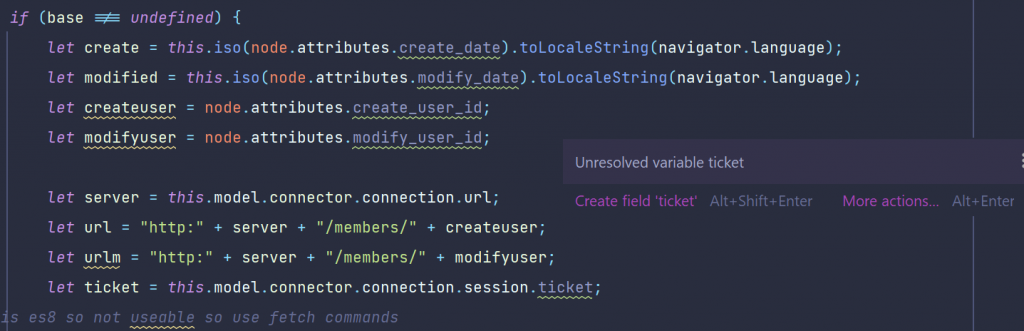
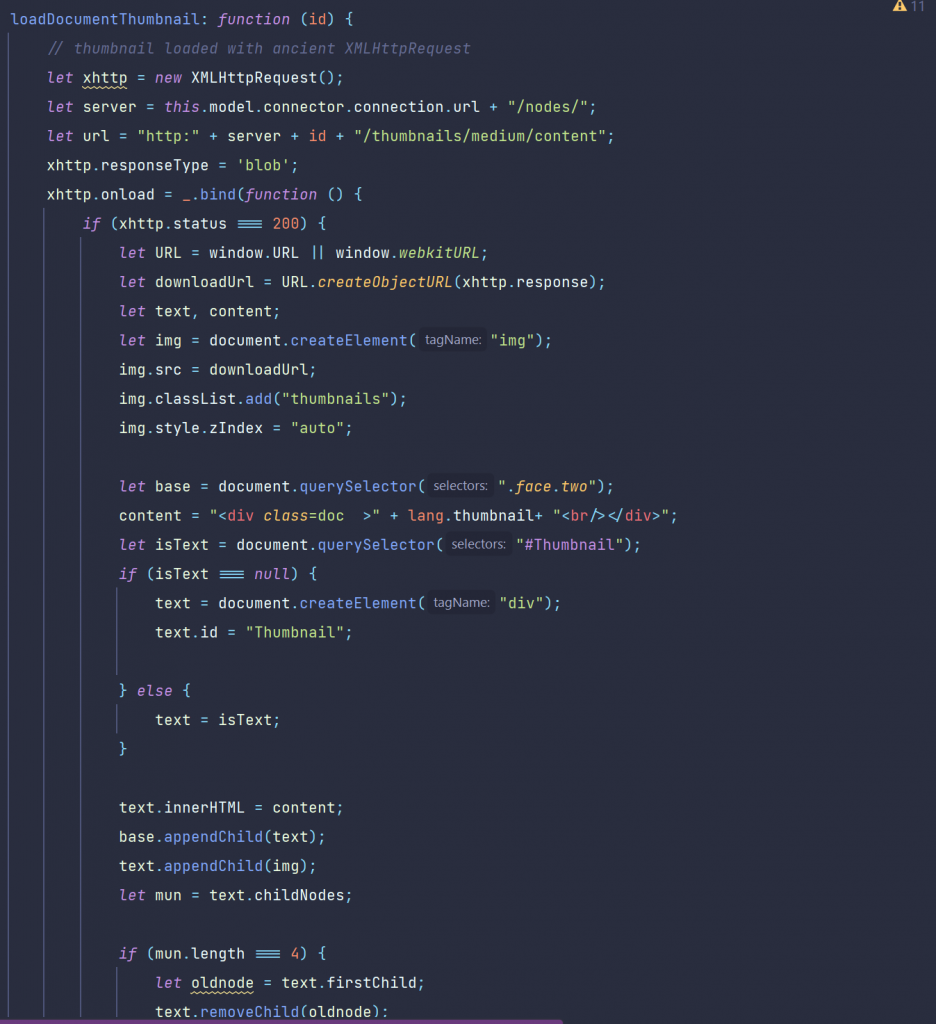
So, to open documents from the Content Server, you need to use a JAVA REST client (Login, Select the document, transfer the document).
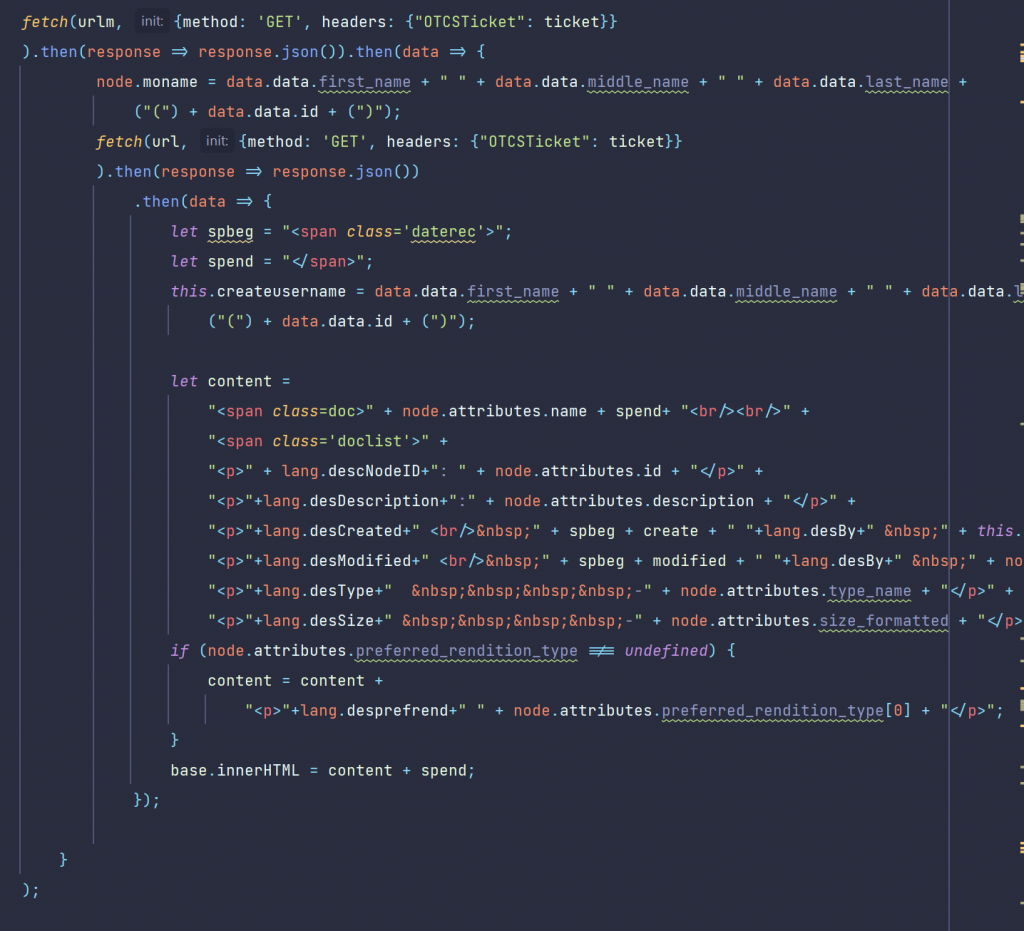
Then use TIKA to extract the text of the document.
Then use openNLP to do all of the AI natural language processing (NLP).
Thats it.
It’s really easy to use Apache TIKA and Apache openNLP in the Content Server environment