
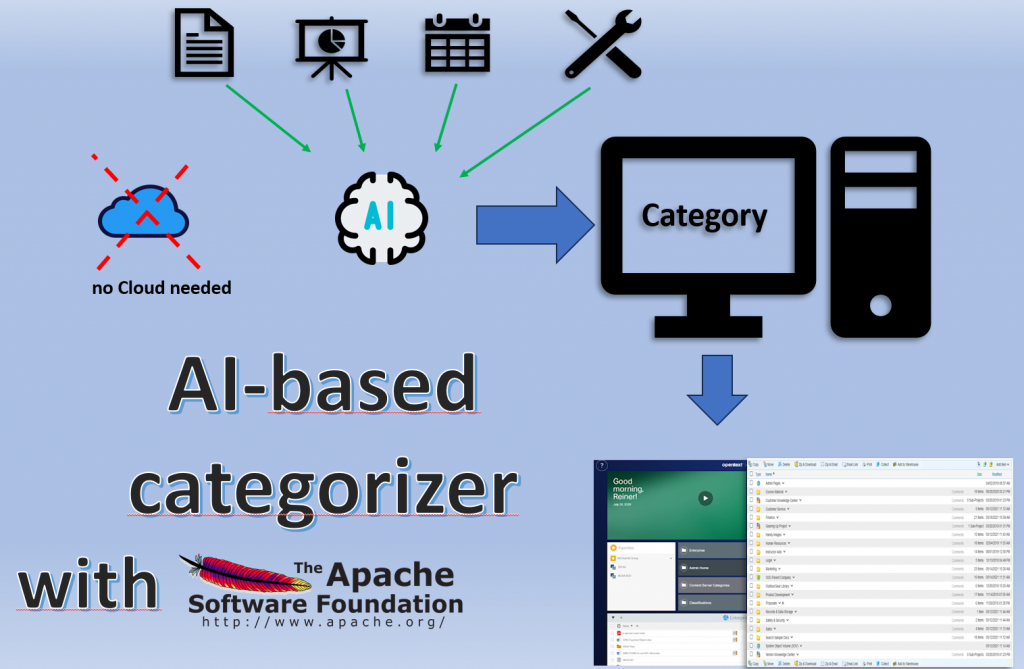
NLP Application: Autocategorizer is a project, based on Open Source Software from Apache and some REST Programming to the Content Server.
Navigation
Example Linguistic Features of NLP
Content Server NLP application examples
Content Server Autocategorizer
Content
- Whats a categorizer?
- Categories will be used per document
- So what is an autocategorizer?
- How does an autocategorizer work?
- Indexers and NERs and a buildin autocategorizer
- Saving in the Content Server (and other systems) with REST
- Training
Whats a categorizer?
Categories are as old as humanity and are used to classify documents. For example, all tax documents can be grouped under the “Tax 2024” category to quickly and safely find all tax documents.
The matching shelf for this is the filing cabinet.

Well, with the increasing use of computers, the filing cabinet has become somewhat out of style.
Categories will be used per document
Below we refer to the categories of OpenText Content Server, but a similar procedure is quite similar for all document programs.
First the categories are defined
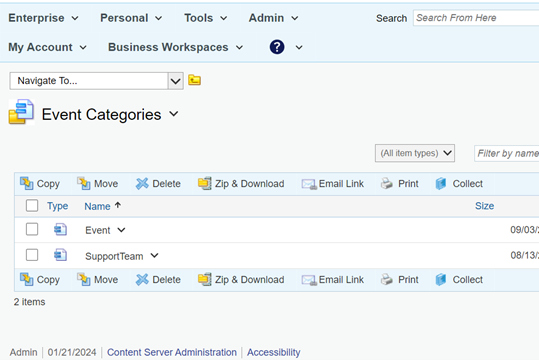
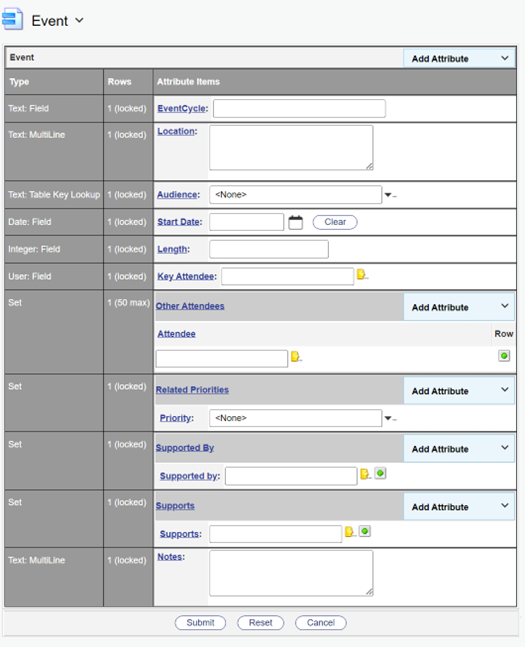
A computer allows the definition of slightly more complex attributes to the categories to make the document easier to find
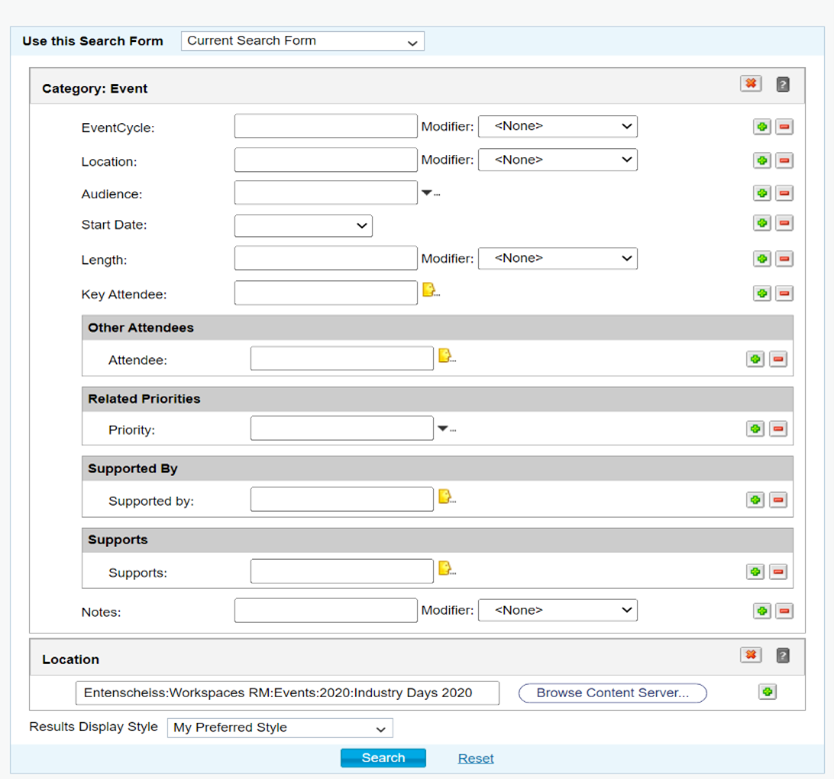
You can also search by category. If you don’t have such a system for assigning categories, a cheap and adaptive auto-categorizer is a good idea.
So what is an autocategorizer?
To put it simply, it is a program that examines the document in order to automatically assign categories and the associated attributes to it.
Nobody has to worry about the organization system or even fear that the document will be categorized incorrectly and is therefore difficult to find again.
How does an autocategorizer work?
It’s first to examine the document in question. For this purpose, the document is converted into pure text form.
Three different approaches are now conceivable at this point of time. At this point, a decision must be made in advance as to which approach will be used. There are three options, an open source Apache indexer, one or more NERs (see below) and finally the built-in document indexer of the open source software.
Indexers and NERs and a buildin autocategorizer
Indexers
First of all, this is a book index that has been used since the beginning of printing. It is a list of terms sorted by page number. The text is simply searched and, for example, the most common index entry is used as a category.

Automatic index creation is available as open source. Extensions, such as the creation of index priorities and the selection of categories based on them, must be discussed and created in advance.
NER
This is a term that stands for “Named Entities Recognition (NER)” in “Natural Language Processing” (a special area of artificial intelligence). An example English sentence searched for “NERs” can produce this output. The proper name “Sebastian Thrun” is recognized, as is 2007 as the date and Google as the company.
The recognition of trained NERs is based on the statistical methods from Bayes or NGram built into the APACHE NLP set.
In this example, these could be the categories “Sebastian Thrun”, “Google” and “2007”, under which this hypothetical
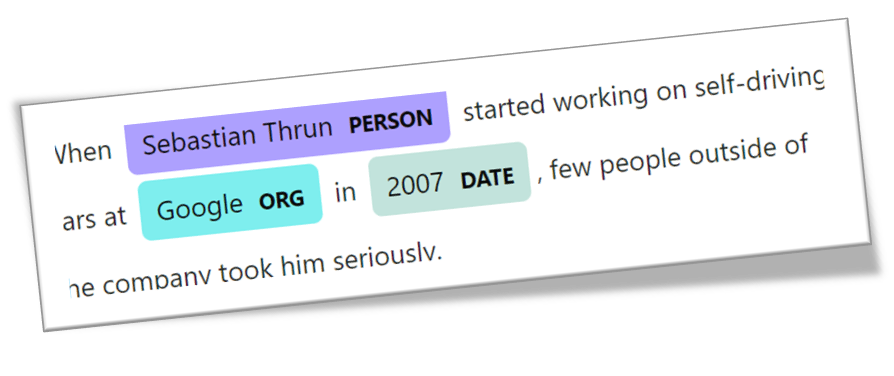
NERs can be direct people, organizations or data and currencies; more advanced NERs must be trained on a customer-specific basis if you do not want to be satisfied with the standard entries.
Built-in document categorizer
This categorizer must be trained in advance so that it recognizes the category and the text to be examined.
Here is an example (a demo of the program) of a fairly abbreviated film database that first contains the classification (Thriller/Romantic) and then a summary of the film’s content.
Thriller An American Muslim man and former Delta Force operator Yusuf Sheen makes a videotape When FBI Special Agent Helen Brody Moss and her team see …
Romantic Krish Malhotra Arjun Kapoor a fresh Engineer from IIT Delhi now a student pursuing his MBA at the IIM Ahmedabad Gujarat comes from a troubled ….
In practical operation, the correct category is picked when the system receives a summary of the film’s content that it has never seen before.
The output of the demo is then (highest probability is 99.99%=Romantic)
Model is successfully trained.
Trained Model is saved locally at : custom_models\en-movie-classifier-ngram.bin
———————————
Category : Probability
———————————
Thriller : 2.1694037140217652E-14
Romantic : 0.9999999999999782
———————————
Romantic : is the predicted category for the given sentence.
Saving in the Content Server (and other systems)
Determining the category and attributes does not require a cloud (of course possible, but not necessary); in the minimum case, the category is determined on an extra system.
Communication takes place from the client to the server using the established standard REST interface (see below).
In the case of the content server, the REST interface is included in the base of the content server.
Then the document and category are saved in the content server.
Training
This is a project where almost everything (except for the training and REST programming) is made from open source software. Some parts still need to be created according to customer requirements
If the categories are to be based on NERs/categories, it is quite likely that these additional NERs/categories will need to be trained first in order to recognize new NERs/categories (e.g. “file number”, “case number”, etc.).
This is required once, but can be repeated many times if new NERs/categories need to be recognized.
This training does not require the cloud; everything can be done directly in the private customer network.