

openNLP command line – openNLP provides a Command Line Interface (CLI) to carry out different operations through the command line. This is part 1 of the command line description. The part 2 is here
Content
Example of the Sentence Detector
Other NLP AI Contentserver Articles
Example Linguistic Features of NLP- Part1
Example Linguistic Features of NLP- Part2
a name and location finder example
Content Server NLP application examples
Content Server Autocategorizer
The Command line
Type “openNLP” to see the complete list of commands
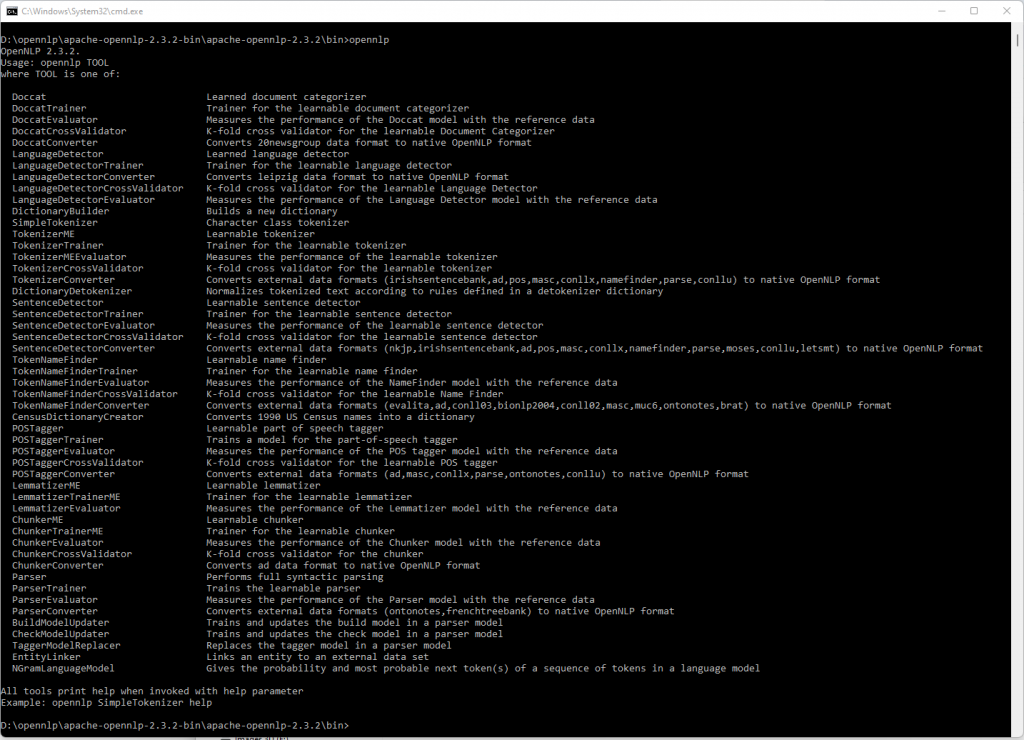
These are runnable jars and can be used directly from the command line.
Lets take a look on two examples on the usage.
Usage
Sentence Detector
Inputfile input.txt
Hello. How are you doing? We at ebit company help you use openNLP and OpenTexts ContentServer. It is the new free AI from Apache.Doing the Sentence Detection
opennlp SentenceDetector <path to models>en-sent.bin < input.txt > output.txtOutput-File output.txt
Loading Sentence Detector model ...
done (0,049s)
Hello.
How are you doing?
We at ebit company help you use openNLP and OpenTexts ContentServer.
It is the new free AI from Apache.
Average: 266,7 sent/s
Total: 4 sent
Runtime: 0.015s
Execution time: 0,081 secondsNamed Entities
Inputfile input.txt
<START:person> Reiner Merz<END> is senior Content Server and AI specialist and
<START:person> Alisa<END> works at the Irish Pub in Stuttgart Doing the Name Find
opennlp TokenNameFinder <path to models>en-ner-person.bin <input.txt > output.txtOutput-File output.txt
Loading Token Name Finder model ...
done (0,582s)
<START:person> Reiner Merz<END> is senior Content Server and AI specialist and
<START:person> Alisa<END> works at the Irish Pub in Stuttgart
Average: 100,0 sent/s
Total: 2 sent
Runtime: 0.02s
Execution time: 0,659 secondsMain Groups
Document Categorizer
This Document Categorizer group has 5 members
- Doccat – Learned document categorizer itself
- DoccatTrainer – Trainer for the learnable document categorizer
- DoccatEvaluator – Measures the performance of the Doccat model with the reference data
- DoccatCrossValidator – K-fold cross validator for the learnable Document Categorizer
- DoccatConverter – Converts 20newsgroup data format to native OpenNLP format

Language Detector
the Language Detector group has 5 members
- LanguageDetector – Learned language detector
- LanguageDetectorTrainer – Trainer for the learnable language detector
- LanguageDetectorConverter – Converts leipzig data format to native OpenNLP format
- LanguageDetectorCrossValidator – K-fold cross validator for the learnable Language Detector
- LanguageDetectorEvaluator – Measures the performance of the Language Detector model with the reference data

The Sentence Detector
The Sentence Detector group hat 5 members
- SentenceDetector – Learnable sentence detector
- SentenceDetectorTrainer – Trainer for the learnable sentence detector
- SentenceDetectorEvaluator – Measures the performance of the learnable sentence detector
- SentenceDetectorCrossValidator – K-fold cross validator for the learnable sentence detector
- SentenceDetectorConverter – Converts external data formats (nkjp,irishsentencebank,ad,pos,masc,conllx,namefinder,parse,moses,conllu,letsmt) to native OpenNLP format

The Name Finder
The Name Finder group has 7 members
- TokenNameFinder – Learnable name finder
- TokenNameFinderTrainer – Trainer for the learnable name finder
- TokenNameFinderEvaluator – Measures the performance of the NameFinder model with the reference data
- TokenNameFinderCrossValidator – K-fold cross validator for the learnable Name Finder
- TokenNameFinderConverter – Converts external data formats (evalita,ad,conll03,bionlp2004,conll02,masc,muc6,ontonotes,brat) to native OpenNLP format
- CensusDictionaryCreator – Converts 1990 US Census names into a dictionary

The POSTagger
The POSTagger group has 5 members
- POSTagger – Learnable part of speech tagger
- POSTaggerTrainer – Trains a model for the part-of-speech tagger
- POSTaggerEvaluator – Measures the performance of the POS tagger model with the reference data
- POSTaggerCrossValidator – K-fold cross validator for the learnable POS tagger
- POSTaggerConverter – Converts external data formats (ad,masc,conllx,parse,ontonotes,conllu) to native OpenNLP format

The Lemmatizer
The Lemmatizer group has 3 members
- LemmatizerME – Learnable lemmatizer
- LemmatizerTrainerME – Trainer for the learnable lemmatizer
- LemmatizerEvaluator – Measures the performance of the Lemmatizer model with the reference data

The Chunker
The Chunker Group has 5 members
- ChunkerME – Learnable chunker
- ChunkerTrainerME – Trainer for the learnable chunker
- ChunkerEvaluator – Measures the performance of the Chunker model with the reference data
- ChunkerCrossValidator – K-fold cross validator for the chunker
- ChunkerConverter – Converts ad data format to native OpenNLP format
