

Apache Tika – Open and extract text from virtually all formats. Its called a “content analysis toolkit”
Its free like openNLP and its used to extract text from virtually all file formats possible.
Content
Using Apache Tika as a command line utility
Apache Tika Example: Extracting MS Office
Goto the start opennlp series of acticles: Starting Page
The complete configuration of our AI Content Server extension is like this:
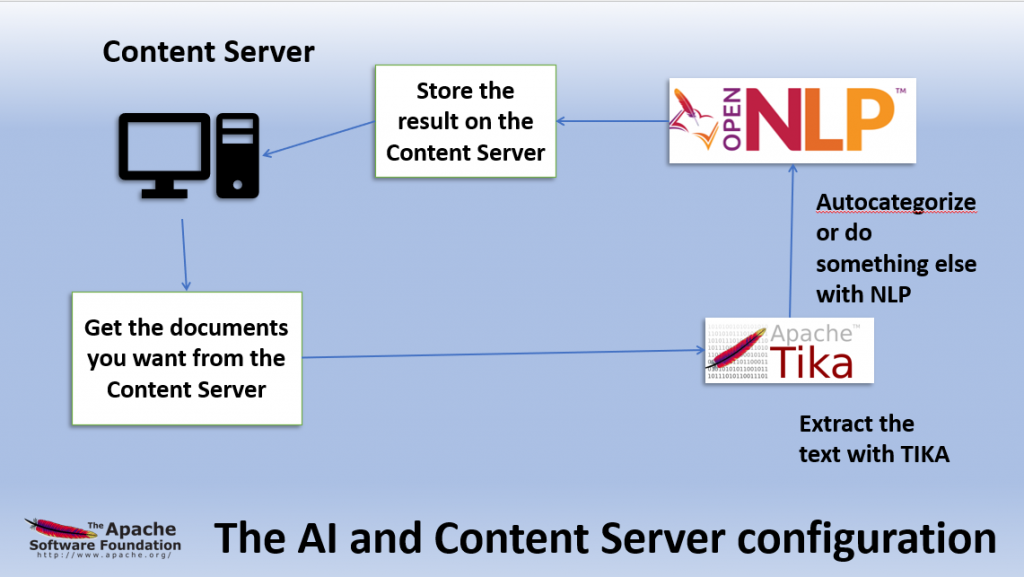
You can get TIKA at https://tika.apache.org/ . How to install is explained on this URL
A nice overview of TIKA is here https://www.tutorialspoint.com/tika/tika_overview.htm
A very nice book on TIKA at Manning https://www.manning.com/books/tika-in-action

Using Apache Tika as a command line utility
The basic usage (w/o programming) is a command line utility. Its used like
usage: java -jar tika-app.jar [option...] [file|port...]
Options:
-? or --help Print this usage message
-v or --verbose Print debug level messages
-V or --version Print the Apache Tika version number
-g or --gui Start the Apache Tika GUI
-s or --server Start the Apache Tika server
-f or --fork Use Fork Mode for out-of-process extraction
--config=<tika-config.xml>
TikaConfig file. Must be specified before -g, -s, -f or the dump-x-config !
--dump-minimal-config Print minimal TikaConfig
--dump-current-config Print current TikaConfig
--dump-static-config Print static config
--dump-static-full-config Print static explicit config
-x or --xml Output XHTML content (default)
-h or --html Output HTML content
-t or --text Output plain text content
-T or --text-main Output plain text content (main content only)
-m or --metadata Output only metadata
-j or --json Output metadata in JSON
-y or --xmp Output metadata in XMP
-J or --jsonRecursive Output metadata and content from all
embedded files (choose content type
with -x, -h, -t or -m; default is -x)
-l or --language Output only language
-d or --detect Detect document type
--digest=X Include digest X (md2, md5, sha1,
sha256, sha384, sha512
-eX or --encoding=X Use output encoding X
-pX or --password=X Use document password X
-z or --extract Extract all attachements into current directory
--extract-dir=<dir> Specify target directory for -z
-r or --pretty-print For JSON, XML and XHTML outputs, adds newlines and
whitespace, for better readability
--list-parsers
List the available document parsers
--list-parser-details
List the available document parsers and their supported mime types
--list-parser-details-apt
List the available document parsers and their supported mime types in apt format.
--list-detectors
List the available document detectors
--list-met-models
List the available metadata models, and their supported keys
--list-supported-types
List all known media types and related information
--compare-file-magic=<dir>
Compares Tika's known media types to the File(1) tool's magic directory
Description:
Apache Tika will parse the file(s) specified on the
command line and output the extracted text content
or metadata to standard output.
Instead of a file name you can also specify the URL
of a document to be parsed.
If no file name or URL is specified (or the special
name "-" is used), then the standard input stream
is parsed. If no arguments were given and no input
data is available, the GUI is started instead.
- GUI mode
Use the "--gui" (or "-g") option to start the
Apache Tika GUI. You can drag and drop files from
a normal file explorer to the GUI window to extract
text content and metadata from the files.
- Batch mode
Simplest method.
Specify two directories as args with no other args:
java -jar tika-app.jar <inputDirectory> <outputDirectory>
Batch Options:
-i or --inputDir Input directory
-o or --outputDir Output directory
-numConsumers Number of processing threads
-bc Batch config file
-maxRestarts Maximum number of times the
watchdog process will restart the child process.
-timeoutThresholdMillis Number of milliseconds allowed to a parse
before the process is killed and restarted
-fileList List of files to process, with
paths relative to the input directory
-includeFilePat Regular expression to determine which
files to process, e.g. "(?i)\.pdf"
-excludeFilePat Regular expression to determine which
files to avoid processing, e.g. "(?i)\.pdf"
-maxFileSizeBytes Skip files longer than this value
Control the type of output with -x, -h, -t and/or -J.
To modify child process jvm args, prepend "J" as in:
-JXmx4g or -JDlog4j.configuration=file:log4j.xml.This stand alone jar is the easiest way to use TIKA.
Apache Tika Example: Extracting MS Office
This is an example of using TIKA with Excel (metadata)
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class MSxcelParse {
public static void main(final String[] args) throws IOException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File("example_msExcel.xlsx"));
ParseContext pcontext = new ParseContext();
//OOXml parser
OOXMLParser msofficeparser = new OOXMLParser ();
msofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}When you run this program, you’ll see this output
Contents of the document:
Sheet1
Name Age Designation Salary
Ramu 50 Manager 50,000
Raheem 40 Assistant manager 40,000
Robert 30 Superviser 30,000
sita 25 Clerk 25,000
sameer 25 Section in-charge 20,000
Metadata of the document:
meta:creation-date: 2006-09-16T00:00:00Z
dcterms:modified: 2014-09-28T15:18:41Z
meta:save-date: 2014-09-28T15:18:41Z
Application-Name: Microsoft Excel
extended-properties:Company:
dcterms:created: 2006-09-16T00:00:00Z
Last-Modified: 2014-09-28T15:18:41Z
Application-Version: 15.0300
date: 2014-09-28T15:18:41Z
publisher:
modified: 2014-09-28T15:18:41Z
Creation-Date: 2006-09-16T00:00:00Z
extended-properties:AppVersion: 15.0300
protected: false
dc:publisher:
extended-properties:Application: Microsoft Excel
Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet
Last-Save-Date: 2014-09-28T15:18:41ZPlease refer to the book or to the pages from Apache for more.