

Spacy is an Python based popular Open Source AI – NLP (natural language processing) package for 75+ languages including supporting Word Vectors. Spacy supports also new graphics processors.
Content
Word vectors and semantic similarity
Goto the start opennlp series of acticles: Starting Page
Spacy vs openNLP Part 1 Pros and Cons
How to find it?
The website is spaCy · Industrial-strength Natural Language Processing in Python.
It has also several downloadable pretrained models, in these languages
- Catalan
- Chinese
- Croatian
- Danish
- Dutch
- English
- Finnish
- French
- German
- Greek
- Italian
- Japanese
- Korean
- Lithuanian
- Macedonian
- Multi-language
- Norwegian Bokmål
- Polish
- Portuguese
- Romanian
- Russian
- Slovenian
- Spanish
- Swedish
- Ukrainian
Package naming conventions
In general, spaCy uses for all pipeline packages to follow the naming convention of [lang]_[name]. For spaCy’s pipelines, there is also chose to divide of the name into three components:
- Type: Capabilities (e.g.
corefor general-purpose pipeline with tagging, parsing, lemmatization and named entity recognition, ordepfor only tagging, parsing and lemmatization). - Genre: Type of text the pipeline is trained on, e.g.
webornews. - Size: Package size indicator,
sm,md,lgortrf.smandtrfpipelines have no static word vectors. For pipelines with default vectors,mdhas a reduced word vector table with 20k unique vectors for ~500k words andlghas a large word vector table with ~500k entries. For pipelines with floret vectors,mdvector tables have 50k entries andlgvector tables have 200k entries.
Example en_core_web_md
For example, en_core_web_md is a medium English model trained on written text , that includes vocabulary, syntax and entities.
The larger models have the word vertors buildin.
| SIZE | MD 40 MB |
| COMPONENTS | tok2vec, tagger, parser, senter, attribute_ruler, lemmatizer, ner |
| PIPELINE | tok2vec, tagger, parser, attribute_ruler, lemmatizer, ner |
| VECTORS | 514k keys, 20k unique vectors (300 dimensions) |
| DOWNLOAD LINK | en_core_web_md-3.7.1-py3-none-any.whl |
| SOURCES | OntoNotes 5 (Ralph Weischedel, Martha Palmer, Mitchell Marcus, Eduard Hovy, Sameer Pradhan, Lance Ramshaw, Nianwen Xue, Ann Taylor, Jeff Kaufman, Michelle Franchini, Mohammed El-Bachouti, Robert Belvin, Ann Houston) ClearNLP Constituent-to-Dependency Conversion (Emory University) WordNet 3.0 (Princeton University) Explosion Vectors (OSCAR 2109 + Wikipedia + OpenSubtitles + WMT News Crawl) (Explosion) |
short summary of the linguistic Capabilities
POS Tagging
After tokenization, spaCy can parse and tag a given Doc. This is where the trained pipeline and its statistical models come in, which enable spaCy to make predictions of which tag or label most likely applies in this context. A trained component includes binary data that is produced by showing a system enough examples for it to make predictions that generalize across the language – for example, a word following “the” in English is most likely a noun.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("IBM is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
If you run that Python code, you'll get
IBM IBM PROPN NNP nsubj XXX True False
is be AUX VBZ aux xx True True
looking look VERB VBG ROOT xxxx True False
at at ADP IN prep xx True True
buying buy VERB VBG pcomp xxxx True False
U.K. U.K. PROPN NNP dobj X.X. False False
startup startup NOUN NN dep xxxx True False
for for ADP IN prep xxx True True
$ $ SYM $ quantmod $ False False
1 1 NUM CD compound d False False
billion billion NUM CD pobj xxxx True Falsethis means
| TEXT | LEMMA | POS | TAG | DEP | SHAPE | ALPHA | STOP |
|---|---|---|---|---|---|---|---|
| IBM | ibm | PROPN | NNP | nsubj | Xxxxx | True | False |
| is | be | AUX | VBZ | aux | xx | True | True |
| looking | look | VERB | VBG | ROOT | xxxx | True | False |
| at | at | ADP | IN | prep | xx | True | True |
| buying | buy | VERB | VBG | pcomp | xxxx | True | False |
| U.K. | u.k. | PROPN | NNP | compound | X.X. | False | False |
| startup | startup | NOUN | NN | dobj | xxxx | True | False |
| for | for | ADP | IN | prep | xxx | True | True |
| $ | $ | SYM | $ | quantmod | $ | False | False |
| 1 | 1 | NUM | CD | compound | d | False | False |
| billion | billion | NUM | CD | pobj | xxxx | True | False |
If you use one of the spacy visualizers, you’ll get this image
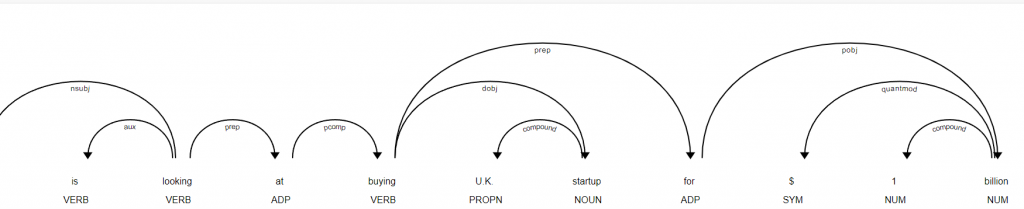
Nice, isn’t it?
Morphology
Inflectional morphology is the process by which a root form of a word is modified by adding prefixes or suffixes that specify its grammatical function but do not change its part-of-speech. We say that a lemma (root form) is inflected (modified/combined) with one or more morphological features to create a surface form. Here are some examples:
| CONTEXT | SURFACE | LEMMA | POS | MORPHOLOGICAL FEATURES |
|---|---|---|---|---|
| I was reading the paper | reading | read | VERB | VerbForm=Ger |
| I don’t watch the news, I read the paper | read | read | VERB | VerbForm=Fin, Mood=Ind, Tense=Pres |
| I read the paper yesterday | read | read | VERB | VerbForm=Fin, Mood=Ind, Tense=Past |
import spacy
nlp = spacy.load(“en_core_web_sm”)
print(“Pipeline:”, nlp.pipe_names)
doc = nlp(“I am going to dinner”)
token = doc[0] # ‘I’
print(token.morph) # ‘Case=Nom|Number=Sing|Person=1|PronType=Prs’
print(token.morph.get(“PronType”)) # [‘Prs’]
if you run this code, you’ll get
Case=Nom|Number=Sing|Person=1|PronType=Prs
['Prs']
Lemmatization
as always, a Lemmatizer takes the word into its basic form
import spacy
# English pipelines include a rule-based lemmatizer
nlp = spacy.load("en_core_web_sm")
lemmatizer = nlp.get_pipe("lemmatizer")
print(lemmatizer.mode) # 'rule'
doc = nlp("I was taking the paper.")
print([token.lemma_ for token in doc])if you run this code, you’ll get
rule
['I', 'be', 'take', 'the', 'paper', '.']
Dependency Parsing
spaCy features a syntactic dependency parser, and has an API for navigating the tree. The parser also powers the sentence boundary detection, and lets you iterate over base noun phrases, or “chunks”.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Credit and mortgage account holders must submit their requests")
span = doc[doc[4].left_edge.i : doc[4].right_edge.i+1]
with doc.retokenize() as retokenizer:
retokenizer.merge(span)
for token in doc:
print(token.text, token.pos_, token.dep_, token.head.text)if you’ll run this code, you’ll get
C:\Users\merz\AppData\Local\anaconda3\python.exe K:\cspython\src\REST\test.py
Credit nmod 0 2 ['account', 'holders', 'submit']
and cc 0 0 ['Credit', 'account', 'holders', 'submit']
mortgage conj 0 0 ['Credit', 'account', 'holders', 'submit']
account compound 1 0 ['holders', 'submit']
holders nsubj 1 0 ['submit']
['credit', 'and', 'mortgage', 'account', 'holder', 'should', 'submit', 'their', 'request']
TEXT DEP N_LEFTS N_RIGHTS ANCESTORS
Credit nmod 0 2 holders, submit
and cc 0 0 holders, submit
mortgage compound 0 0 account, Credit, holders, submit
account conj 1 0 Credit, holders, submit
holders nsubj 1 0 submitFinally, the .left_edge and .right_edge attributes can be especially useful, because they give you the first and last token of the subtree. This is the easiest way to create a Span object for a syntactic phrase. Note that .right_edge gives a token within the subtree – so if you use it as the end-point of a range, don’t forget to +1!
Named Entity Recognition
spaCy has an fast statistical entity recognition system, that assigns labels to contiguous spans of tokens. The default trained pipelines can identify a variety of named and numeric entities, including companies, locations, organizations and products. You can add arbitrary classes to the entity recognition system, and update the model with new examples.
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("San Francisco considers banning delivery robots")
# document level
ents = [(e.text, e.start_char, e.end_char, e.label_) for e in doc.ents]
print(ents)
# token level
ent_san = [doc[0].text, doc[0].ent_iob_, doc[0].ent_type_]
ent_francisco = [doc[1].text, doc[1].ent_iob_, doc[1].ent_type_]
print(ent_san) # ['San', 'B', 'GPE']
print(ent_francisco) # ['Francisco', 'I', 'GPE']
if you’ll run that code, you’ll get
C:\Users\merz\AppData\Local\anaconda3\python.exe K:\cspython\src\REST\test.py
[('San Francisco', 0, 13, 'GPE')]
['San', 'B', 'GPE']
['Francisco', 'I', 'GPE']
If you use the builtin visualizer of spacy to visualizte the NER, you’ll get this:
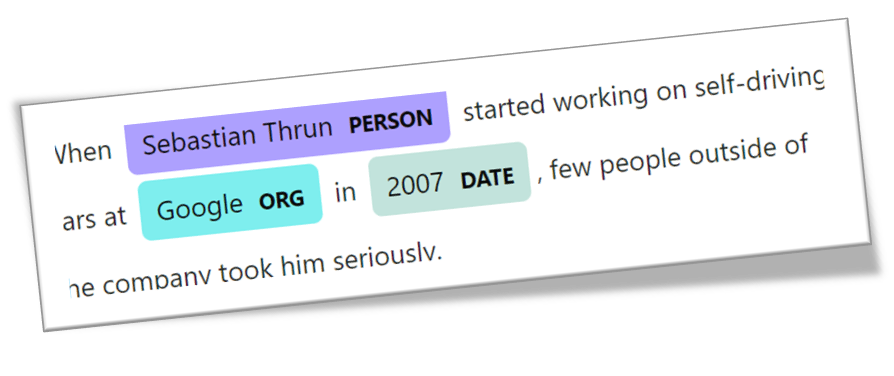
Word vectors and semantic similarity
import spacy
nlp = spacy.load("de_core_news_lg")
tokens = nlp("dog cat banane afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)if run run that code, you’ll get this
C:\Users\merz\AppData\Local\anaconda3\python.exe K:\cspython\src\REST\test.py
hund True 45.556004 False
katze True 40.768963 False
banane True 22.76727 False
afskfsd False 0.0 TrueThe words “hund” (in German its a “dog”) , “katze” (in German its a “cat”) and “banane” (in German its a “banana”) are all pretty common in German, so they’re part of the pipeline’s vocabulary, and come with a vector. The word “afskfsd” on the other hand is a lot less common and out-of-vocabulary – so its vector representation consists of 300 dimensions of 0, which means it’s practically nonexistent
spaCy can compare two objects, and make a prediction of how similar they are. Predicting similarity is useful for building recommendation systems or flagging duplicates. For example, you can suggest a user content that’s similar to what they’re currently looking at, or label a support ticket as a duplicate if it’s very similar to an already existing one.